
yeon's 👩🏻💻
RNN (many-to-one stacking) 본문
https://engineer-mole.tistory.com/25
[python/Tensorflow2.0] RNN(Recurrent Neural Network) ; many to one stacking
1. Stacking이란? CNN에서 convolution layer를 여러 개를 썼듯 ,RNN도 마찬가지로 여러 개를 쌓을 수 있다. 이를 multi layered RNN 또는 stacked RNN이라고 얘기한다. CNN에서 convolution layer를 여러 개 쌓..
engineer-mole.tistory.com
위 블로그를 필사하며 공부
* 모든 텍스트와 이미지의 출처는 위 블로그입니다.
(더불어 해당 포스트와 제 글은 김성훈 교수님의 '모두를 위한 딥러닝'을 바탕으로 제작되었음을 명시합니다.
https://www.boostcourse.org/ai212/lecture/43752?isDesc=false)
1. Stacking이란?
CNN에서 convolution layer를 여러 개 썼듯, RNN도 마찬가지로 여러 개를 쌓을 수 있다.
-> 이를 multi layered RNN 또는 stacked RNN 이라고 얘기한다.
CNN에서 convolution layer를 여러 개 쌓았을 때, input 이미지에 가까운 convolution layer은 edge와 같은 글로벌한 feature을 뽑을 수 있고, output에 가까운 convolution layer은 좀 더 abstract한 feature을 뽑을 수 있듯이,
RNN에서도 stacked RNN을 활용해 비슷한 효과를 얻을 수 있다.

- 자연어 처리 분야의 stacked RNN 관련 여러 논문에서 input에 가까운 RNN의 hidden states가 sementic information(의미적 정보)보다 syntatic information(문법적 정보)을 상대적으로 더 잘 인코딩 하고 있으며,
- 반대로 output에 가까운 RNN의 hidden states는 sementic information을 syntatic information보다 더욱 잘 인코딩 하고 있음을 실증적으로 파악하기 때문에 자연어 처리에 stacked RNN이 다양하게 활용되고 있다.
2. Stacked RNN 구현
이전의 many-to-one 구조를 활용하는 방식과 크게 다르지 않으며 차이점은 RNN을 여러 개 활용하는 stacked RNN을 many-to-one으로 사용한다는 점

- 시퀀스를 tokenization 한 뒤 embedding layer을 거쳐 어떤 numeric vector로 표현된 각 토큰을 stacked RNN이 순서대로 읽어들인다.
- stacked RNN을 구성하고 있는 RNN 중 t번째 시점의 토큰(마지막 줄 빨간색)과 t-1 시점의 hidden states(초록색)를 받아서 t번째 시점의 hidden states(초록색)를 생성한다.

- 두 번째 RNN은 t번째 시점에 첫 번째 rnn의 hidden states와 t-1번째 시점은 두 번째 rnn의 hidden states를 받아서 t번째 시점에 hidden states를 생성한다.

- 이와 같은 방식은 rnn을 몇 개 staking 했느냐에 상관없이 동일하게 적용된다.
- 마지막 토큰을 읽었을 때 나온 출력과 정답의 loss를 계산하고, 이 loss로 stacked RNN을 back propagation을 통해 학습한다.
- 이번에는 문장을 분류해보자
(1) Importing Libraries
# setup
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import Sequential, Model
from tensorflow.keras.preprocessing.sequence import pad_sequences
%matplotlib inline
print(tf.__version__)
(2) Preparing Dataset
# example data
sentences = ['What I cannot create, I do not understand.',
'Intellecuals solve problems, geniuses prevent them',
'A person who never made a mistake never tied anything new.',
'The same equations have the same solutions.']
y_data = [1, 0, 0, 1]- y_data에서 1은 richard feynman이 했던 말, 0은 albert eisntein이 했던 말 ..
- 예제 데이터로 주어진 각 sentence를 캐릭터의 시퀀스로 간주하고 문제를 풀 것이며,
- 이를 위해 (지난 번 처럼) 토큰이 이러한 캐릭터를 integer index로 맵핑하고 있는 토큰의 딕셔너리를 만들어야 함
# creating a token dictionary
char_set = ['<pad>'] + sorted(list(set(''.join(sentences))))
idx2char = {idx: char for idx, char in enumerate(char_set)}
char2idx = {char: idx for idx, char in enumerate(char_set)}
print(char_set)
print(idx2char)
print(char2idx)
# converting sequence of token to sequence of indices
x_data = list(map(lambda sentence: [char2idx.get(char) for char in sentence], sentences))
x_data_len = list(map(lambda sentence: len(sentence), sentences))
print(x_data)
print(x_data_len)
print(y_data)
- 이전보다 시퀀스의 길이가 훨씬 길어졌다.
- 이렇게 길이가 긴 시퀀스를 다룰 때에는 단순 RNN보다는 Long Short - Term Memory Network(LSTM) 또는 Gated Recurrent Unit(GRU) 등을 활용하는 것이 좋다.
- 여기서는 stacked RNN 구조로 작성하였다.
# padding the sequence of indices
max_sequence = 58
x_data = pad_sequences(sequences=x_data, maxlen=max_sequence, padding='post', truncating='post')
# checking data
print(x_data)
print(x_data_len)
print(y_data)
- sentence의 sequence가 다른 문제를 해결
(3) Creating Model
# creating simple rnn for "many to one" classification without dropout
num_classes = 2
hidden_dims = [10, 10]
input_dim = len(char2idx)
output_dim = len(char2idx)
one_hot = np.eye(len(char2idx))
model = Sequential()
model.add(layers.Embedding(input_dim=input_dim, output_dim=output_dim,
trainable=False, mask_zero=True, input_length=max_sequence,
embeddings_initializer=keras.initializers.Constant(one_hot)))
model.add(layers.SimpleRNN(units=hidden_dims[0], return_sequences=True))
model.add(layers.TimeDistributed(layers.Dropout(rate=.2)))
model.add(layers.SimpleRNN(units=hidden_dims[1]))
model.add(layers.Dropout(rate=.2))
model.add(layers.Dense(units=num_classes))- 이전과 마찬가지로 mask_zero=True 옵션을 통해 시퀀스 중 0으로 padding된 부분을 연산에 포함하지 않을 수 있다.
trainable=False 옵션으로 one-hot vector를 training하지 않을 수 있다.
- return_sequences=True: 두 번째 rnn이 필요한 형태,
즉 (data dimension, max sequences, input dimension)의 형태로 데이터를 리턴한다.
- TimeDistributed와 Dropout을 이용하는 이유는
stacked RNN이 shallow RNN에 비해 모델의 capacity가 높은 구조이므로 overfitting될 가능성이 크기 때문.
- 따라서 rnn이 각 토큰을 처리한 hidden states에 dropout을 걸어 overfitting을 방지해준다.
(두 번째 layer에서도 마찬가지)
model.summary()
(4) Training model
# creating loss function
def loss_fn(model, x, y, training):
return tf.reduce_mean(tf.keras.losses.sparse_categorical_crossentropy(
y_true=y, y_pred=model(x, training), from_logits=True))
# creating an optimizer
lr = .01
epochs = 30
batch_size = 2
opt = tf.keras.optimizers.Adam(learning_rate=lr)
# generating data pipeline
tr_dataset = tf.data.Dataset.from_tensor_slices((x_data, y_data))
tr_dataset = tr_dataset.shuffle(buffer_size=4)
tr_dataset = tr_dataset.batch(batch_size=batch_size)
print(tr_dataset)- 우리가 설계한 stacked RNN 구조는 Dropout을 활용한다.
- Dropout은 training할 때 활용하되 inference 단계에서는 활용하지 않으므로
이를 control하기 위해 loss function에 training argument를 두어 이를 컨트롤한다.
# training
tr_loss_hist = []
for epoch in range(epochs):
avg_tr_loss = 0
tr_step = 0
for x_mb, y_mb in tr_dataset:
with tf.GradientTape() as tape:
tr_loss = loss_fn(model, x=x_mb, y=y_mb, training=True)
grads = tape.gradient(target=tr_loss, sources=model.variables)
opt.apply_gradients(grads_and_vars=zip(grads, model.variables))
avg_tr_loss += tr_loss
tr_step += 1
else:
avg_tr_loss /= tr_step
tr_loss_hist.append(avg_tr_loss)
if (epoch + 1) % 5 == 0:
print('epoch: {:3}, tr_loss: {:.3f}'.format(epoch+1, avg_tr_loss.numpy()))
(5) Checking performance
yhat = model.predict(x_data)
yhat = np.argmax(yhat, axis=-1)
print('acc: {:.2%}'.format(np.mean(yhat == y_data)))
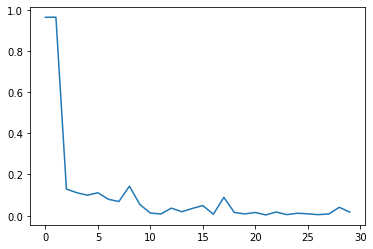
plt.plot(tr_loss_hist)
'Computer 💻 > Deep Learning' 카테고리의 다른 글
| Support Vector Machine (서포트 벡터 머신) (0) | 2022.01.10 |
|---|---|
| [cs231n] 3. Loss Functions and Optimization | Linear Classification, Loss Function, Softmax, Optimization, Generalization, Regularization, Cross-validation, Gradient Descent 등 (0) | 2022.01.10 |
| RNN (many-to-one) (0) | 2021.10.29 |
| RNN in TensorFlow(텐서플로우) (0) | 2021.10.28 |
| RNN이란? (2) (0) | 2021.10.28 |



